In this post, we'll take a look at the Frank-Wolfe Algorithm also known as the Conditional Gradient Method, an algorithm particularly suited for solving problems with compact domains. Like the Proximal Gradient and Accelerated Proximal Gradient algorithms, Frank-Wolfe requires we exploit problem structure to quickly solve a mini-optimization problem. Our reward for doing so is a converge rate of \(O(1/\epsilon)\) and the potential for extremely sparse solutions.
Returning to my valley-finding metaphor, Frank-Wolfe is a bit like this,
- Look around you and see which way points the most downwards
- Walk as far as possible in that direction until you hit a wall
- Go back in the direction you started, stop part way along the path, then repeat.
How does it work?
Frank-Wolfe is designed to solve problems of the form,
where \(D\) is compact and \(f\) is differentiable. For example, in \(R^n\) any closed and bounded set is compact. The algorithm for Frank-Wolfe is then,
Input: Initial iterate \(x^{(0)}\)
- For \(t = 0, 1, 2, \ldots\)
- Let \(s^{(t+1)} = \arg\min_{s \in D} \langle \nabla f(x^{(t)}), s \rangle\)
- If \(g(x) = \langle \nabla f(x^{(t)}), x - s^{(t+1)} \rangle \le \epsilon\), break
- Let \(x^{(t+1)} = (1 - \alpha^{(t)}) x^{(t)} + \alpha^{(t)} s^{(t+1)}\)
The proof relies on \(\alpha^{(t)} = 2 / (t+2)\), but line search works as well. The intuition for the algorithm is that at each iteration, we minimize a linear approximation to \(f\),
then take a step in that direction. We can immediately see that if \(D\) weren't compact, \(s^{(t)}\) would go off to infinity.
Upper Bound One nice property of Frank-Wolfe is that it comes with its own upper bound on \(f(x^{(t)}) - f(x^{*})\) calculated during the course of the algorithm. Recall the linear upper bound on \(f\) due to convexity,
Since,
we know that \(\nabla f(x^{(t)})^T (x^{(t)} - x^{*}) \le \nabla f(x^{(t)})^T (x^{(t)} - s^{(t+1)})\) and thus,
A Small Example
For this example, we'll minimize a simple univariate quadratic function constrained to lie in an interval,
Its derivative is given by \(2(x-0.5) + 2\), and since we are dealing with real numbers, the minimizers of the linear approximation must be either \(-1\) or \(2\) if the gradient is positive or negative, respectively. We'll use a stepsize of \(\alpha^{(t)} = 2 / (t+2)\) as prescribed by the convergence proof in the next section.
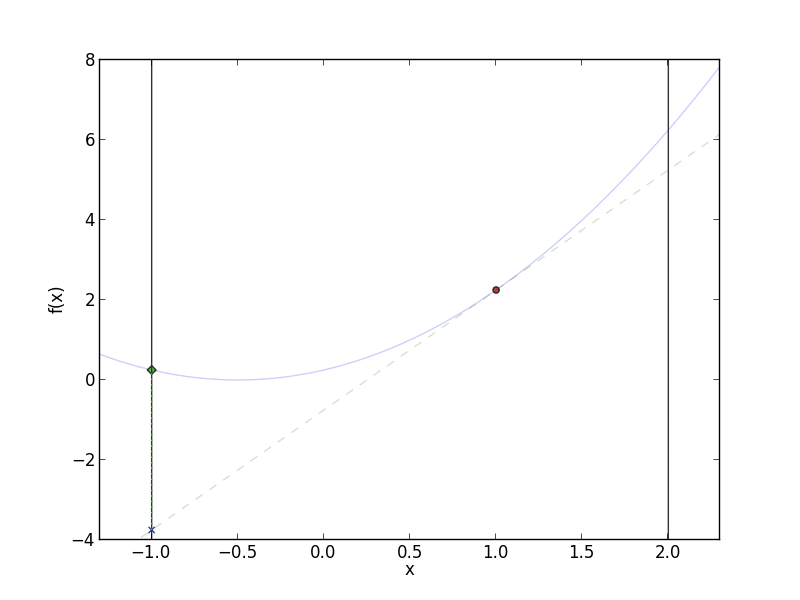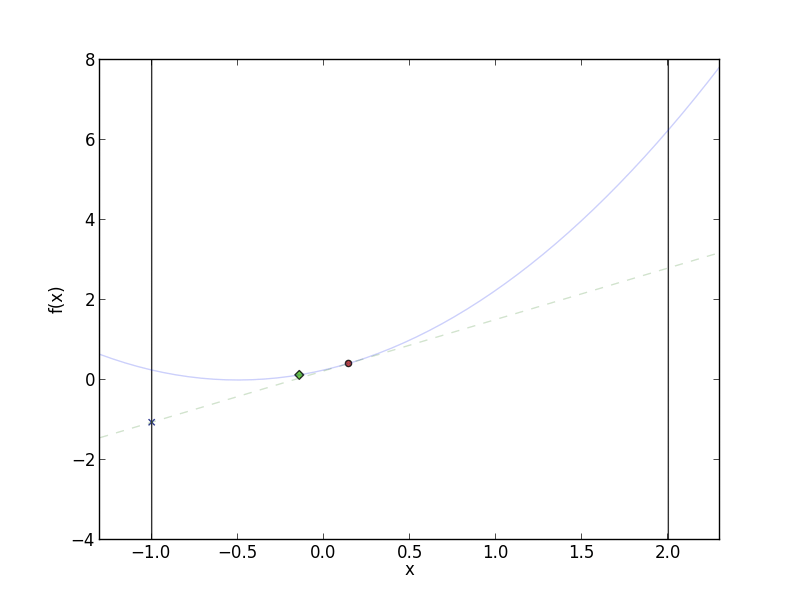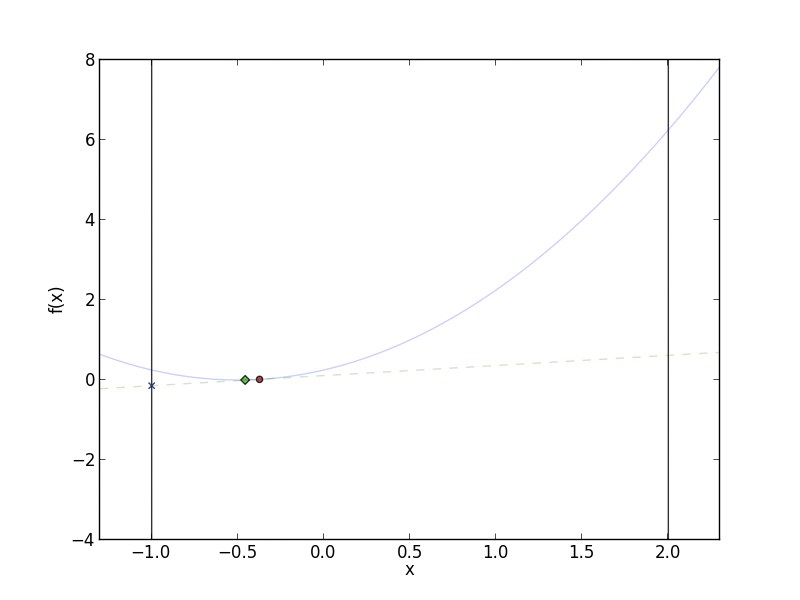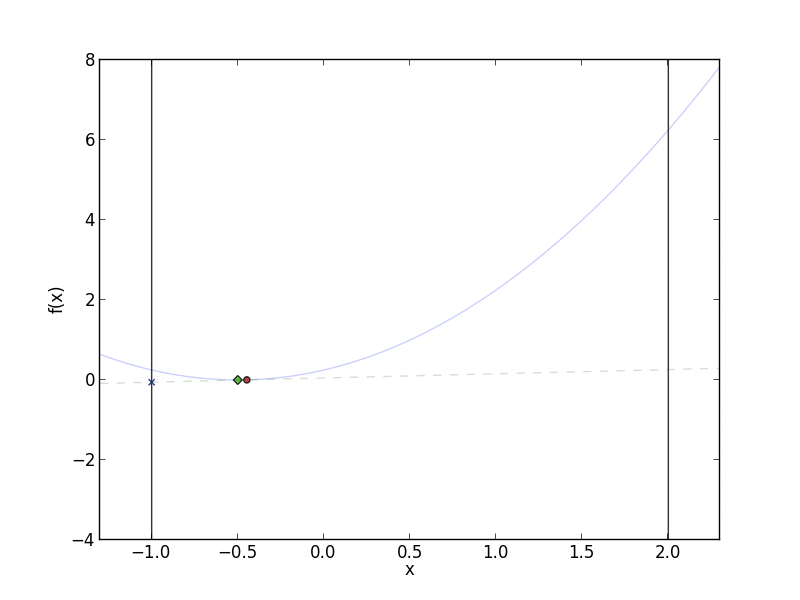 Frank-Wolfe in action. The red circle is the current value for
$f(x^{(t)})$, and the green diamond is $f(x^{(t+1)})$. The dotted line is
the linear approximation to $f$ at $x^{(t)}$. Notice that at each step,
Frank-Wolfe stays closer and closer to $x^{(t)}$ when moving in the
direction of $s^{(t+1)}$.
Frank-Wolfe in action. The red circle is the current value for
$f(x^{(t)})$, and the green diamond is $f(x^{(t+1)})$. The dotted line is
the linear approximation to $f$ at $x^{(t)}$. Notice that at each step,
Frank-Wolfe stays closer and closer to $x^{(t)}$ when moving in the
direction of $s^{(t+1)}$.
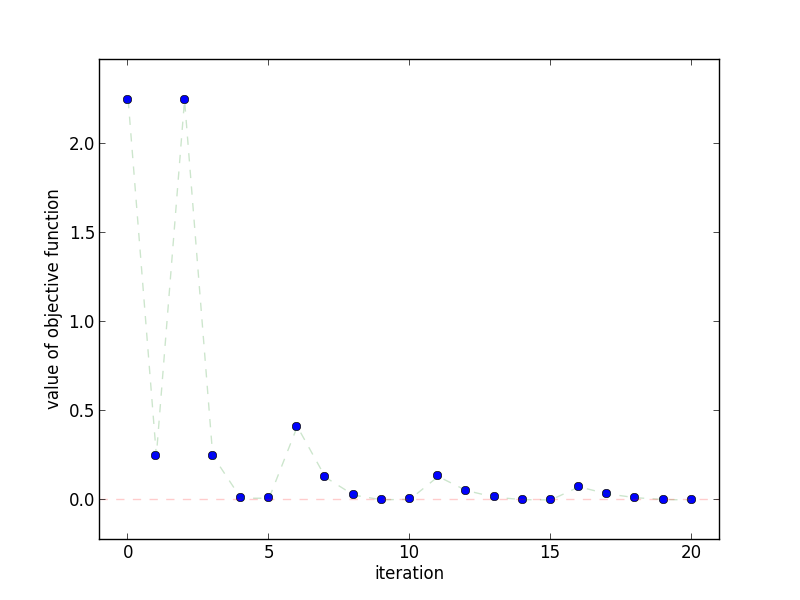 This plot shows how quickly the objective function decreases as the
number of iterations increases. Notice that it does not monotonically
decrease, as with Gradient Descent.
This plot shows how quickly the objective function decreases as the
number of iterations increases. Notice that it does not monotonically
decrease, as with Gradient Descent.
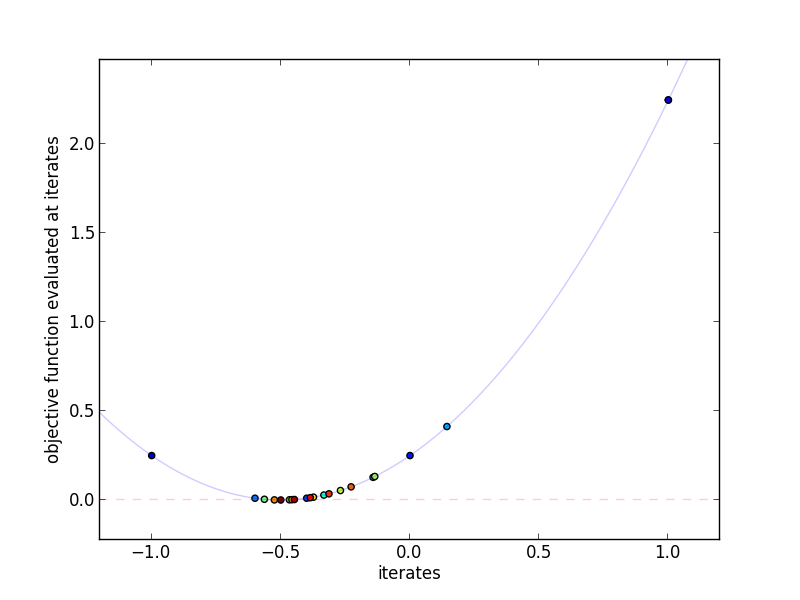 This plot shows the actual iterates and the objective function evaluated at
those points. More red indicates a higher iteration number. Since
Frank-Wolfe uses linear combinations of $s^{(t+1)}$ and $x^{(t)}$, it
tends to "bounce around" a lot, especially in earlier iterations.
This plot shows the actual iterates and the objective function evaluated at
those points. More red indicates a higher iteration number. Since
Frank-Wolfe uses linear combinations of $s^{(t+1)}$ and $x^{(t)}$, it
tends to "bounce around" a lot, especially in earlier iterations.
Why does it work?
We begin by making the two assumptions given earlier,
- \(f\) is convex, differentiable, and finite for all \(x \in D\)
- \(D\) is compact
Assumptions First, notice that we never needed to assume that a solution \(x^{*}\) exists. This is because \(D\) is compact and \(f\) is finite, meaning \(x\) cannot get bigger and bigger to make \(f(x)\) arbitrarily small.
Secondly, we never made a Lipschitz assumption on \(f\) or its gradient. Since \(D\) is compact, we don't have to -- instead, we get the following for free. Define \(C_f\) as,
This immediate implies the following upper bound on \(f\) for all \(x, y \in D\) and \(\alpha \in [0,1]\),
Proof Outline The proof for Frank-Wolfe is surprisingly simple. The idea is to first upper bound \(f(x^{(t+1)})\) in terms of \(f(x^{(t)})\), \(g(x^{(t)})\), and \(C_f\). We then transform this per-iteration bound into a bound on \(f(x^{(t)}) - f(x^{*})\) depending on \(t\) using induction. That's it!
Step 1 Upper bound \(f(x^{(t+1)})\). As usual, we'll denote \(x^{+} \triangleq x^{(t+1)}\), \(x \triangleq x^{(t)}\), \(s^{+} \triangleq s^{(t+1)}\), and \(\alpha \triangleq \alpha^{(t)}\). We begin by using the upper bound we just obtained for \(f\) in terms of \(C_f\), substituting \(x^{+} = (1 - \alpha) x + \alpha s^{+}\) and then \(g(x) = \nabla f(x)^T (x - s^{+})\),
Step 2 Use induction on \(t\). First, recall the upper bound on \(f(x) - f(x^{*}) \le g(x)\) we derived above. Let's add \(-f(x^{*})\) into what we got from Step 1, then use the upper bound on \(f(x) - f(x^{*})\) to get,
Now, we employ induction on \(t\) to show that,
We'll assume that the step size is \(\alpha^{(t)} = \frac{2}{t+2}\), giving us \(\alpha^{(0)} = 2 / (0+2) = 1\) and the base case,
Next, for the recursive case, we use the inductive assumption on \(f(x) - f(x^{*})\), the definition of \(\alpha^{(t)}\), and some algebra,
Thus, if we want an error tolerance of \(\epsilon\), we need \(O(\frac{1}{\epsilon})\) iterations to find it. This matches the convergence rate of Gradient Descent an Proximal Gradient Descent, but falls short of their accelerated brethren.
When should I use it?
Like Proximal Gradient, efficient use of Frank-Wolfe requires solving a mini-optimization problem at each iteration. Unlike Proximal Gradient, however, this mini-problem will lead to unbounded iterates if the input space is not compact -- in other words, Frank-Wolfe cannot directly be applied when your domain is all of \(R^{n}\). However, there is a very special case wherein Frank-Wolfe shines.
Sparsity The primary reason machine learning researchers have recently taken an interest in Frank-Wolfe is because in certain problems the iterates \(x^{(t)}\) will be extremely sparse. Suppose that \(D\) is a polyhedron defined by a set of linear constraints. Then \(s^{(t)}\) is a solution to a Linear Program, meaning that each \(s^{(t)}\) lies on one of the vertices of the polyhedron. If these vertices have only a few non-zero entries, then \(x^{(t)}\) will too, as \(x^{(t)}\) is a linear combination of \(s^{(1)} \ldots s^{(t)}\). This is in direct contrast to gradient and proximal based methods, wherein \(x^{(t)}\) is the linear combination of a set of non-sparse gradients.
Atomic Norms One particular case where Frank-Wolfe shines is when minimizing \(f(x)\) subject to \(||x|| \le c\) where \(|| \cdot ||\) is an "atomic norm". We say that \(||\cdot||\) is an atomic norm if \(||x||\) is the smallest \(t\) such that \(x/t\) is in the convex hull of a finite set of points \(\mathcal{A}\), that is,
For example, \(||x||_1\) is an atomic norm with \(\mathcal{A}\) being the set of all vectors with only one \(+1\) or one \(-1\) entry. In these cases, finding \(\arg\min_{||s|| \le c} \langle \nabla f(x), s \rangle\) is tantamount to finding which element of \(\mathcal{A}\) minimizes \(\langle \nabla f(x), s \rangle\) (since \(\text{Conv}(\mathcal{A})\) defines a polyhedron). For a whole lot more on Atomic Norms, see this tome by Chandrasekaranm et al.
Extensions
Step Size The proof above relied on a step size of \(\alpha^{(t)} = \frac{2}{t+2}\), but as usual Line Search can be applied to accelerate convergence.
Approximate Linear Solutions Though not stated in the proof above, another cool point about Frank-Wolfe is that you don't actually need to solve the linear mini-problem exactly, but you will still converge to the optimal solution (albet at a slightly slower rate). In particular, assume that each mini-problem can be solved approximately with additive error \(\frac{\delta C_f}{t+2}\) at iteration \(t\),
then Frank-Wolfe's rate of convergence is
The proof for this can be found in the supplement to Jaggi's excellent survey on Frank-Wolfe for machine learning.
Linear Invariance
Another cool fact about Frank-Wolfe is that it's linearly invariant -- that is, if you rotate and scale the space, nothing changes about the convergence rate. This is in direct contrast to many other methods which depend on the condition number of a function (for functions with Hessians, this is the ratio between the largest and smallest eigenvalues, \(\sigma_{\max} / \sigma_{\min})\).
Suppose we transform our input space with a surjective (that is, onto) linear transformation \(M: \hat{D} \rightarrow D\). Let's now try to solve the problem,
Let's look at the solution to the per-iteration mini-problem we need to solve for Frank-Wolfe,
In other words, we will find the same \(s\) if we solve in the original space, or if we find \(\hat{s}\) and then map it back to \(s\). No matter how \(M\) warps the space, Frank-Wolfe will do the same thing. This also means that if there's a linear transformation you can do to make the points of your polyhedron sparse, you can do it with no penalty!
References
Proof of Convergence, Linear Invariance Pretty much everything in this article comes from Jaggi's fantastic article on Frank-Wolfe for machine learning.
Reference Implementation
def frank_wolfe(minisolver, gradient, alpha, x0, epsilon=1e-2):
"""Frank-Wolfe Algorithm
Parameters
----------
minisolver : function
minisolver(x) = argmin_{s \in D} <x, s>
gradient : function
gradient(x) = gradient[f](x)
alpha : function
learning rate
x0 : array
initial value for x
epsilon : float
desired accuracy
"""
xs = [x0]
iteration = 0
while True:
x = xs[-1]
g = gradient(x)
s_next = minisolver(g)
if g * (x - s_next) <= epsilon:
break
a = alpha(iteration=iteration, x=x, direction=s_next)
x_next = (1 - a) * x + a * s_next
xs.append(x_next)
iteration += 1
return xs
def default_learning_rate(iteration, **kwargs):
return 2.0 / (iteration + 2.0)
if __name__ == '__main__':
import os
import numpy as np
import pylab as pl
import yannopt.plotting as plotting
### FRANK WOLFE ALGORITHM ###
# problem definition
function = lambda x: (x - 0.5) ** 2 + 2 * x
gradient = lambda x: 2 * (x - 0.5) + 2
minisolver = lambda y: -1 if y > 0 else 2 # D = [-1, 2]
x0 = 1.0
# run gradient descent
iterates = frank_wolfe(minisolver, gradient, default_learning_rate, x0)
### PLOTTING ###
plotting.plot_iterates_vs_function(iterates, function,
path='figures/iterates.png', y_star=0.0)
plotting.plot_iteration_vs_function(iterates, function,
path='figures/convergence.png', y_star=0.0)
# make animation
iterates = np.asarray(iterates)
try:
os.makedirs('figures/animation')
except OSError:
pass
for t in range(len(iterates)-1):
x = iterates[t]
x_plus = iterates[t+1]
s_plus = minisolver(gradient(x))
f = function
g = gradient
f_hat = lambda y: f(x) + g(x) * (y - x)
xmin, xmax = plotting.limits([-1, 2])
ymin, ymax = -4, 8
pl.plot(np.linspace(xmin ,xmax), function(np.linspace(xmin, xmax)), alpha=0.2)
pl.xlim([xmin, xmax])
pl.ylim([ymin, ymax])
pl.xlabel('x')
pl.ylabel('f(x)')
pl.plot([xmin, xmax], [f_hat(xmin), f_hat(xmax)], '--', alpha=0.2)
pl.vlines([-1, 2], ymin, ymax, color=np.ones((2,3)) * 0.2, linestyle='solid')
pl.scatter(x, f(x), c=[0.8, 0.0, 0.0], marker='o', alpha=0.8)
pl.scatter(x_plus, f(x_plus), c=[0.0, 0.8, 0.0], marker='D', alpha=0.8)
pl.vlines(x_plus, f_hat(x_plus), f(x_plus), color=[0.0,0.8,0.0], linestyle='dotted')
pl.scatter(s_plus, f_hat(s_plus), c=0.35, marker='x', alpha=0.8)
pl.savefig('figures/animation/%02d.png' % t)
pl.close()